Любой сайт получает информацию, которая выводится на экран пользователя, с помощью специальных интерфейсов. Один из самых распространенных интерфейсов — это API (Application Programming Interface). С помощью API можно скачивать информацию с сайта по заданному шаблону. Сегодня в рубрике — простая пошаговая инструкция о том, что такое API и как с ним работать, на примере сайта Федеральной налоговой службы России — от проекта «Если быть точным».
Инструмент — API
API — это набор шаблонов, своего рода цифровая бюрократия, правила, по которым можно общаться с программой. Вы отправляете шаблонный запрос и получаете ответ в понятном и заранее определенном формате. Подробнее о том, что такое API, можно почитать тут.
Некоторые API-интерфейсы создаются специально для того, чтобы пользователи получали данные. Например, несколько сервисов API есть у платформы проверки и обогащения данных DaData. Другие известные примеры — API проекта Госзатраты, API сайта Госдумы, API со статистическим показателями Центрального банка или API государственного адресного регистра.
Порядок работы с такими сервисами подробно документируется. Разработчики API создают инструкции, в которых описано, какие запросы можно отправлять и в каком формате, в каком виде приходит ответ. Иногда (как в случае некоторых сервисов DaData) доступ к API платный, а число запросов ограничено.
У использования документированных и недокументированных API есть три основных преимущества.
1. Больше данных: иногда через API возвращается больше информации, чем отображается на сайте.
2. Надежность: так как такие интерфейсы создаются в технических целях, они редко сильно меняются, значит, можно регулярно собирать нужные данные. Правда, иногда официальные ведомства скрывают такие интерфейсы после журналистских расследований.
3. Масштабируемость: скачать данные с помощью кода через API может быть проще, чем выгружать данные вручную.
Но чаще API, с помощью которых сайт получает данные, создаются в технических целях. То есть данные на сайт поступают через API, но как с ним работать, нигде не написано, потому что создатели сайта не предполагали, что к нему будут обращаться внешние пользователи. Такие API называют «недокументированными».
Технически здесь все работает так же, как и в документированных API, но, заходя на сайт, вы не знаете, какие интерфейсы там есть. Однако их можно находить и использовать для автоматической выгрузки данных.
Примеры использования
На сайте Росприроднадзора в Реестре объектов, загрязняющих окружающую среду, в 2023 году в карточках объектов отображалась только общая масса выбросов загрязняющих веществ. А в API, который передавал эти данные сайту, масса выбросов была разбита по конкретным загрязняющим веществам. Воспользовавшись таким недокументированным API, «Если быть точным» оценили, где расположены самые опасные загрязняющие объекты и какие самые опасные вещества они выбрасывают. Правда, через несколько месяцев после публикации Росприроднадзор удалил API, а совсем недавно закрыл и весь реестр.
Другой пример — портал бухгалтерской отчетности ФНС, на котором данные бухгалтерских и финансовых отчетов компаний тоже передаются через недокументированный API. Если научиться с ним работать, то получится, например, выгрузить данные о финансовых результатах организаций, которые вас интересуют.
API нередко используют в журналистских расследованиях. В 2019 году американские журналисты и исследователи обнаружили, что «умные» дверные звонки со встроенными камерами используются правоохранителями — и сеть таких устройств слежки постоянно растет. Для этого они с помощью недокументированного API выгрузили данные приложения Ring Neighbors, в котором владельцы «умных» звонков делились с соседями видео- и текстовыми сообщениями об обстановке в их районе. Другого способа получить такие данные не было.
Другой пример — исследование BBC о доступности гормональной терапии для женщин. Авторы, используя недокументированное API, собрали данные о расположении клиник Национальной службы здравоохранения, в которых работают специалисты по женскому здоровью, и выяснили, что в 59% районах их нет. Поскольку в других источниках таких данных не было, альтернативой API был бы ручной сбор данных. Это заняло бы гораздо больше времени, чем автоматическая выгрузка через API.
Пошаговая инструкция: ищем недокументированный API на примере портала ФНС
Разберемся, как с минимальными навыками программирования, используя только функции для разработчиков (DevTools) в браузере Google Chrome или Firefox, найти недокументированный API.
Шаг 0. Открываем сайт. Заранее сказать, на каких страницах сайта используется API, сложно. Вероятно, вам понадобится повторять шаги, описанные ниже, несколько раз. Но чаще всего API используется там, где информация выдается в структурированном виде по многим объектам (например, на странице есть списки из множества других страниц или таблицы). В случае портала ФНС такая страница открывается, если воспользоваться функцией расширенного поиска портала бухгалтерской отчетности.
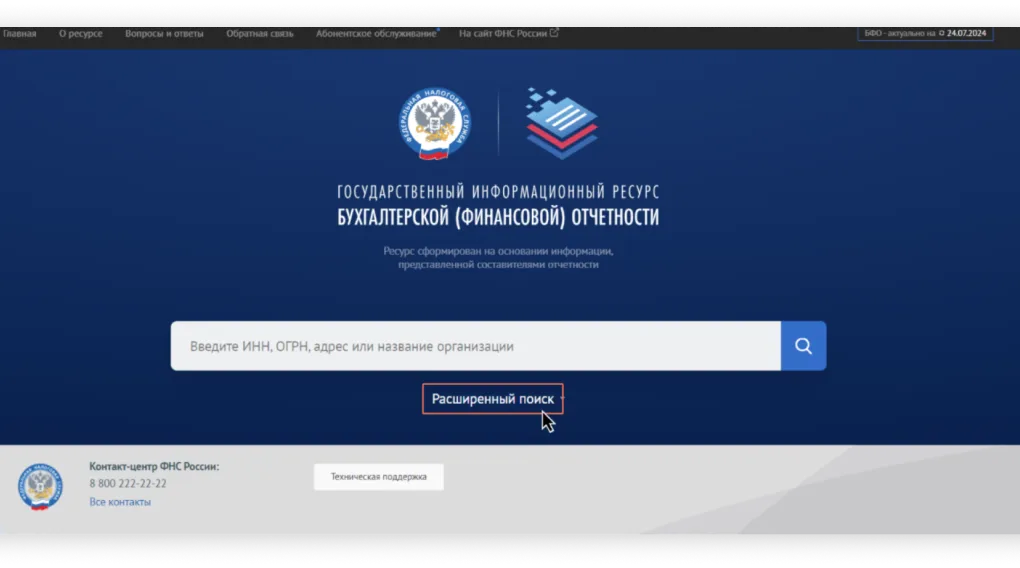
Шаг 1. Открываем панель инструментов веб-разработчика. Чтобы сделать это в Google Chrome, достаточно кликнуть правой кнопкой мышки в любом месте веб-страницы и выбрать пункт «Просмотреть код». Не перепутайте: пункт «Просмотр кода страницы» предназначен для других целей. Есть и другие способы открыть панель инструментов: кнопкой F12, сочетанием клавиш Ctrl+Shift+I в Windows или Command+Option+I в macOS, а также через меню, нажав на три точки → «Дополнительные инструменты» → «Инструменты разработчика».
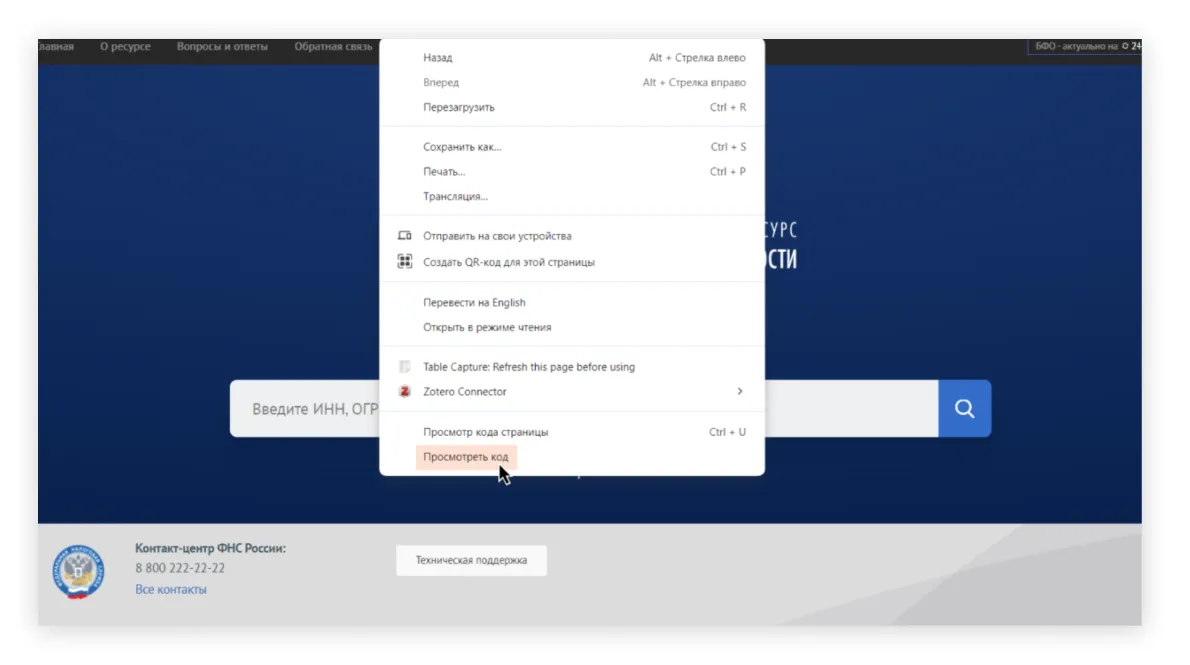
Откроется окно с большим количеством различных элементов. Например, на панели Elements можно увидеть исходный код, из которого собирается та веб-страница, которую вы открываете. Там есть и другие полезные функции, но нас будет интересовать вкладка Network — именно она позволяет смотреть, через какие интерфейсы браузер получает информацию, и, в частности, находить API.
Шаг 2. Переходим во вкладку Network панели инструментов. В ней отображаются запросы ко внутренним и внешним ресурсам и их результаты. Именно здесь можно найти запросы, которые передаются через недокументированные API.
Все, что вы видите на сайте, приходит из какого-то источника. Текст, картинки, данные, код сайта хранятся на удаленном сервере и должны попасть к вам на устройство и отобразиться в браузере.
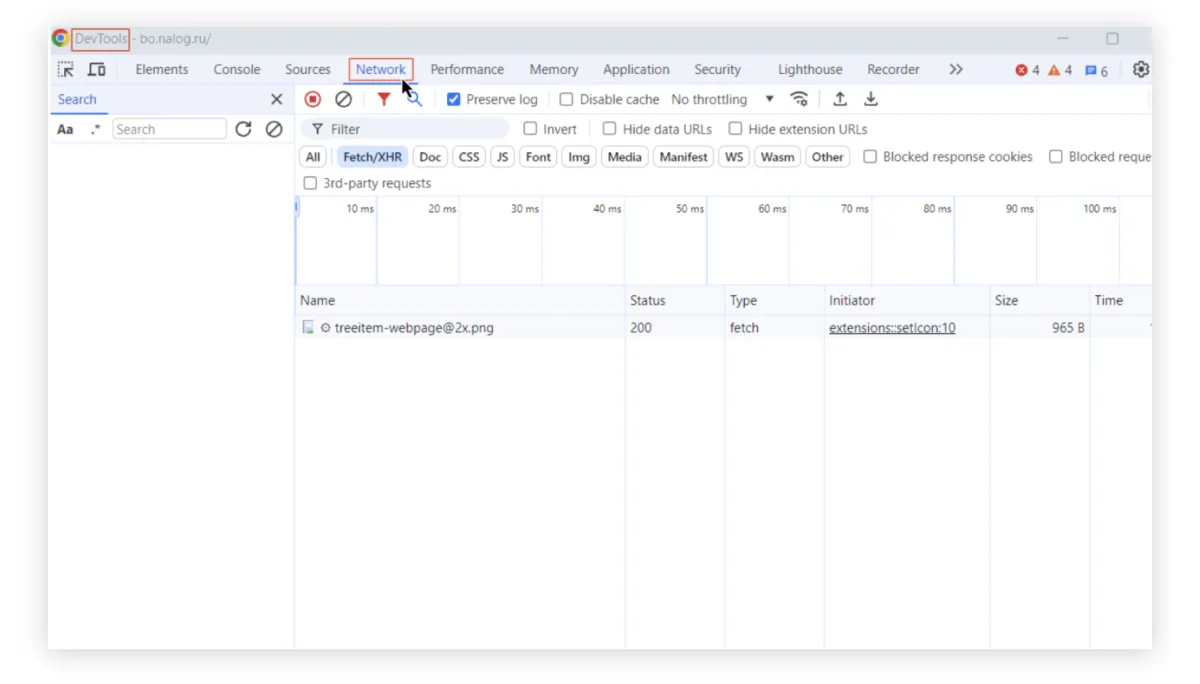
Шаг 3. Открываем страницу с результатами запроса. Теперь сверните «Панель инструментов разработчика» и через опцию расширенного поиска на сайте ФНС выберите все отчеты за 2023 год («Расширенный поиск» → «Отчетный период» → 2023 год). После этого вернитесь в окно «Панели инструментов разработчика».
На других сайтах на этом этапе вам будет нужно или обновить страницу, на которой вы ищете недокументированный API, или найти на сайте ту страницу, на которую, как вы предполагаете, передаются данные через недокументированный API.
Если вы сначала открыли страницу сайта и только потом панель инструментов, то во вкладке Network ничего не будет (как на скрине выше) — все необходимые данные уже были переданы. Нужно обновить страницу или, например, нажать на конкретную компанию, чтобы во вкладке Network отобразились запросы, через которые ваше устройство будет получать данные с удаленного сервера.
Во вкладке Network на панели инструментов вы увидите большое количество различных типов запросов. Например, там есть гифки (Type: gif), есть код (Type: script). Это все элементы, из которых собирается веб-страница.
Нас будет интересовать тип Fetch/XHR (API, доступный в скриптовых языках браузеров, таких как JavaScript), который как раз используется для передачи данных. Чтобы было проще искать нужные запросы, на вкладке Network есть фильтры, которые позволяют отбирать нужные типы запросов (All — все, Fetch/XHR — данные через API скриптовых языков, Img — картинки и другие). Если вдруг вы не видите запросов во вкладке Network, то стоит проверить, настроен ли фильтр на нужный тип, или выбрать опцию All.
Видим, что с типом fetch есть запрос organizations/?allFieldsMatch=False&period=2023&page=0. Даже из названия понятно, что этот запрос возвращает данные по организациям за 2023 год.
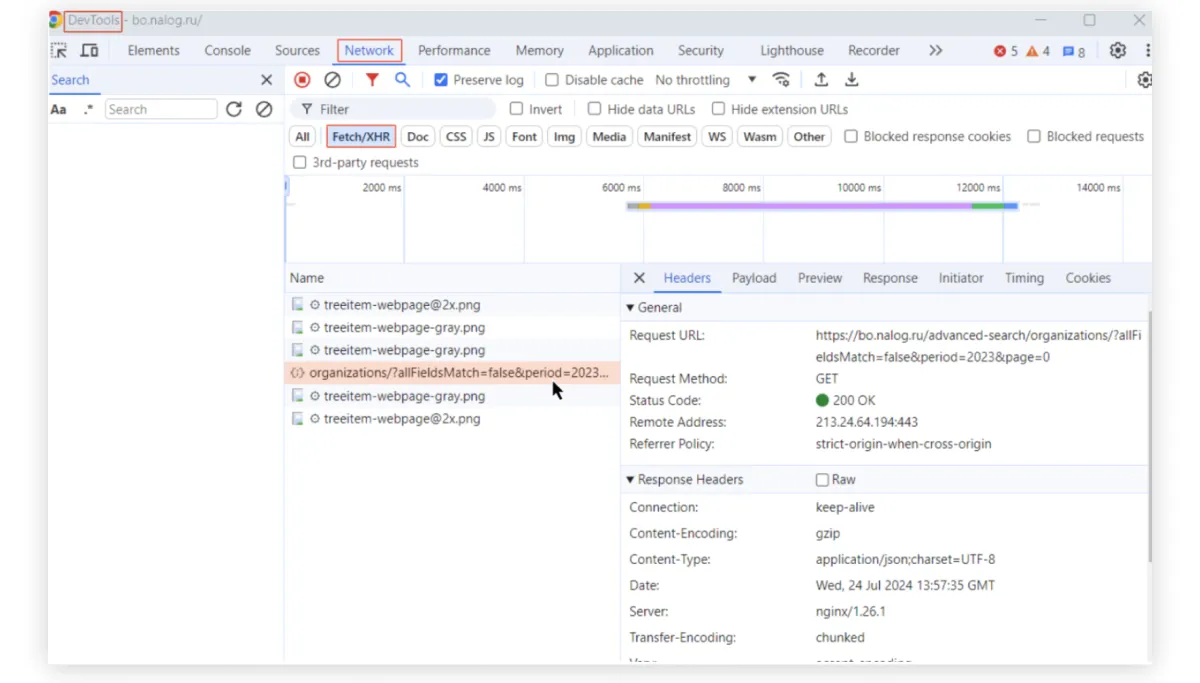
Шаг 4. Изучаем выдачу. Давайте кликнем на него. Может возникнуть вопрос: как сразу понять, какой запрос отвечает за доставку данных на сайт? Честный ответ — сразу никак. Придется вручную посмотреть разные запросы: какие у них названия, какие параметры запроса, что возвращается.
Но есть несколько признаков, которые помогут определить, что запрос возвращает именно данные:
— большой объем информации — чем больше данных, тем больше будет весить ответ на запрос;
— осмысленные названия — обычно даже в недокументированных API разработчики стараются называть методы так, чтобы было примерно понятно, за что они отвечают;
— в запросе есть знак «?», который сигнализирует о наличии параметров, которые можно в него передавать.
После клика на конкретный запрос откроется новое окно. В нем есть вкладка Headers. В ней описана структура запроса, которую ваш браузер отправил на сервер. Как мы и говорили, запрос не произвольный, а имеет ряд обязательных элементов. В частности, есть URL-ссылка в поле Request URL: https://bo.nalog.ru/advanced-search/organizations/?allFieldsMatch=false&period=2023&page=0
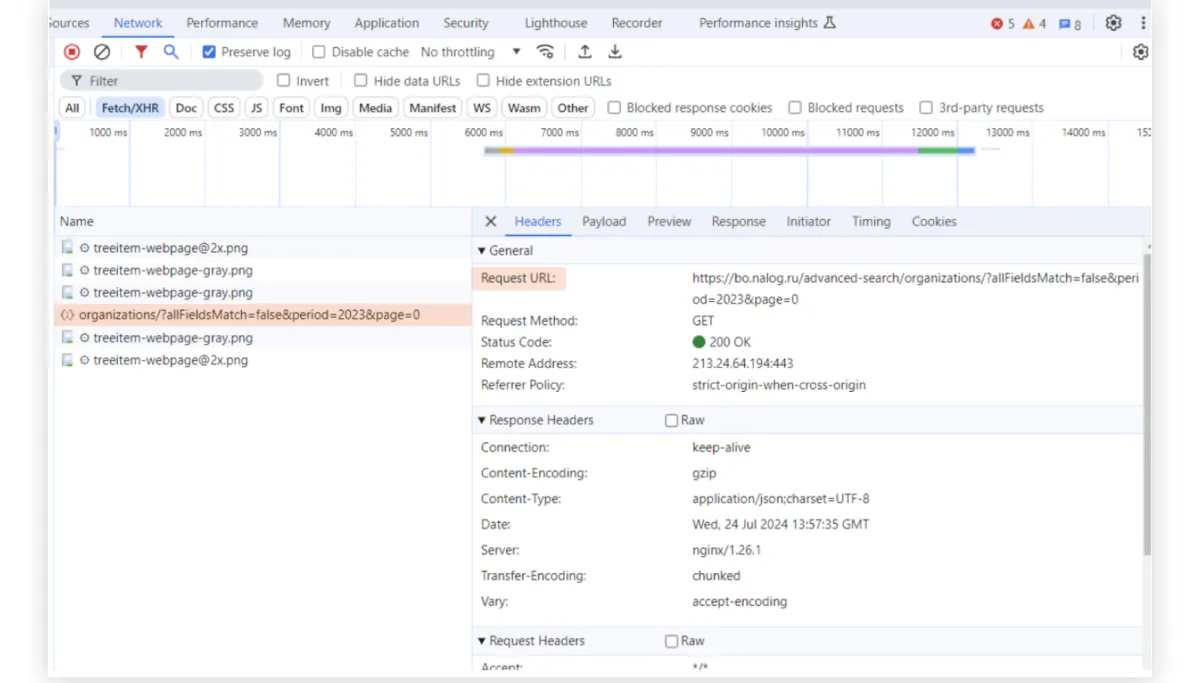
Ответ, полученный на запрос, отображается во вкладке Response. Именно здесь мы видим те данные, которые вернул API. Выглядит все достаточно сложно, но формат ответа опять стандартизован. Как правило, ответы возвращаются в JSON-формате. Это пары «ключ — значение», где ключи заранее известны, а значение для каждой компании свое.
В нашем случае, например, по ключу id указано значение 29827 — это уникальный идентификатор первой компании из выдачи, для которой есть данные об отчетности в 2023 году. Есть и номер ИНН этой компании в поле inn, и аккуратно разбитый на отдельные элементы адрес юридического лица.
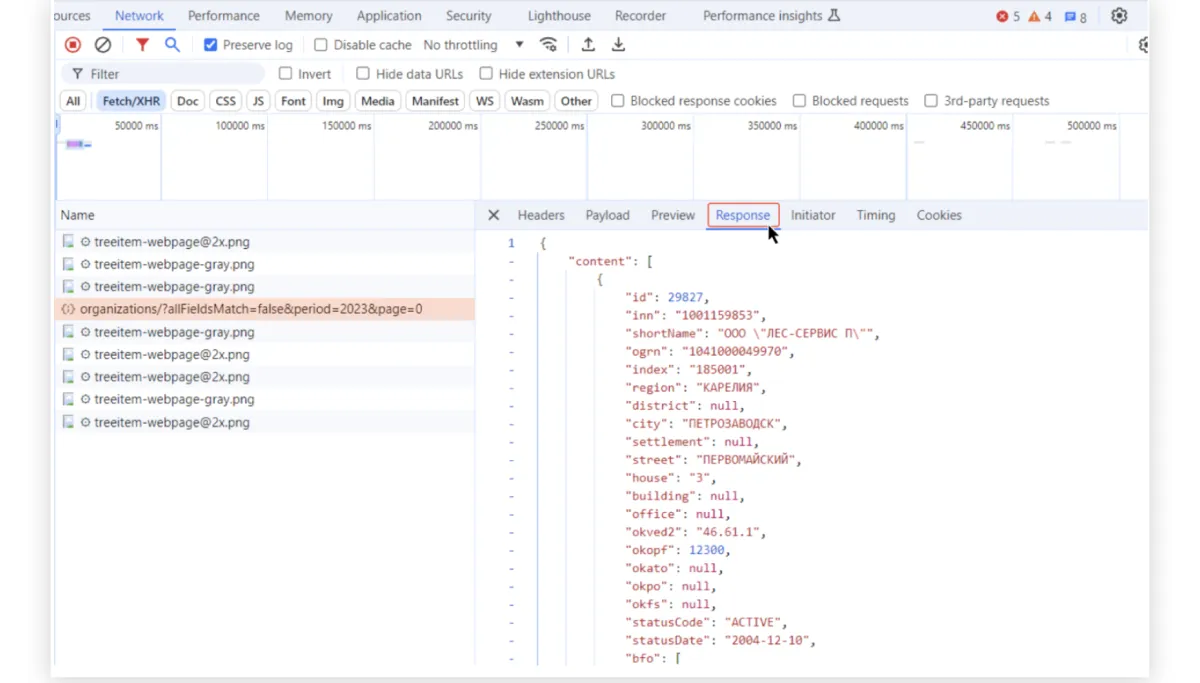
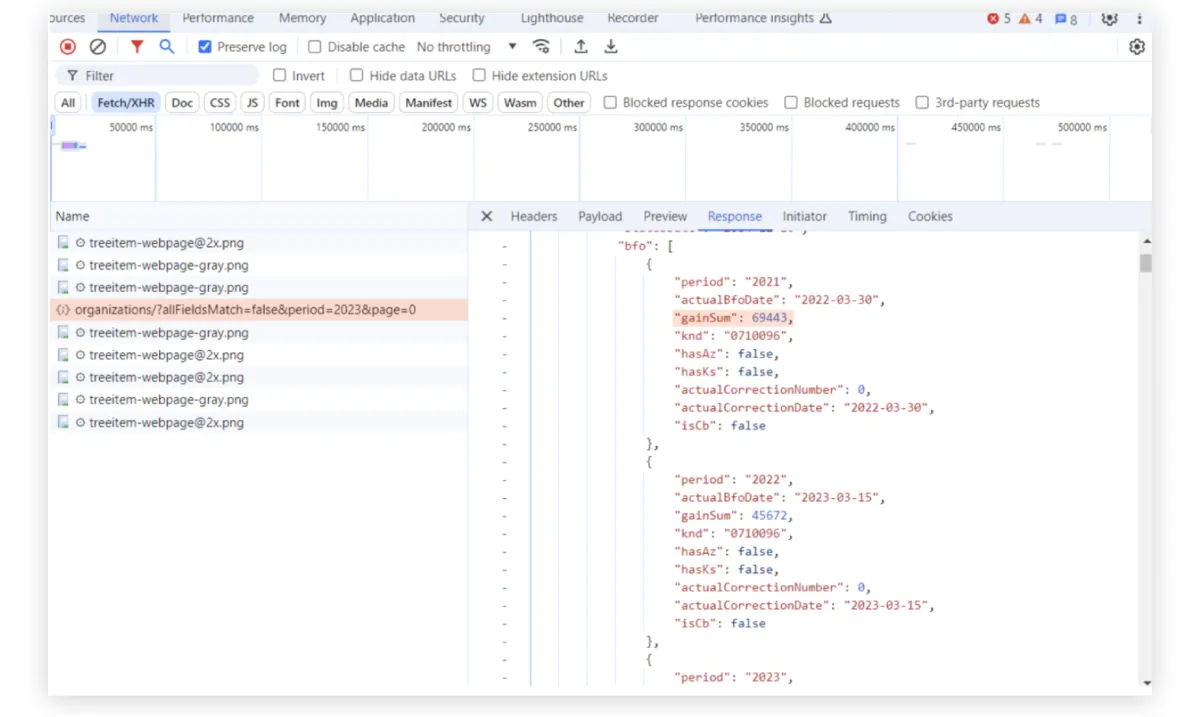
Данных вернулось довольно много. Если полистать дальше, то мы увидим те данные, которые на сайте еще даже не отобразились. Например, суммы полученной выручки по годам.
На сайте «Если быть точным» вы можете также прочитать, как пошагово автоматизировать процесс выгрузки и сбора данных с помощью кода на Python и автоматизировать сбор большого объема данных. Если при чтении этого гайда у вас появились вопросы или что-то не получилось, пишите в бот «Если быть точным» или вступайте в чат проекта про открытые данные.
Мера предосторожности
При работе с недокументированными API обращайте внимание на условия опубликованных на них данных. Если условия сайта прямо запрещают выгрузку, лучше этого не делать. Также всегда следует помнить о правилах работы с отдельными типами данных, например, с персональными данными. Даже если есть техническая возможность выгрузить их с помощью недокументированного API, это не всегда законно.
Что мне с этого?
Иногда разработчики сайта составляют инструкции, как ими пользоваться, но нередко встречаются и «недокументированные API». Умение находить такие API на сайтах сильно упрощает выгрузку данных, а иногда даже позволяет скачать больше данных, чем видно обычному пользователю на сайте.
— В рамках проекта Narco Files издания Cuestión Pública и Berlingske и ОССRP (Международная ассоциация журналистов-расследователей) отслеживают глобальный маршрут перевозки кокаина из Колумбии. Статистика изъятий партий кокаина в Колумбии не публикуется официально и оказалась в распоряжении журналистов благодаря утечке более 7 млн электронных писем из Министерства юстиции Колумбии. На основании этих данных журналисты смогли изучить 1764 случая изъятия колумбийского кокаина в 2016–2022 годы. Примерно три четверти всех эпизодов касалось перевозки кокаина на небольших судах вроде рыболовецких лодок.
— Издание Kloop изучило криминальные отчеты из кыргызских СМИ и создало базу данных более тысячи младенцев, брошенных и найденных в общественных туалетах, в полях, у жилых домов и квартир и даже в мусорных баках. Журналисты детально расследуют 115 историй и разбираются в социальной подоплеке этого явления.
— Информагентство The Outlier изучило результаты лучших женщин-марафонцев мира и пришло к выводу, что 82 из 100 самых быстрых спортсменок оказались родом из Кении и Эфиопии. Причем в этих странах есть несколько регионов, где рождается больше всего быстрых женщин, среди них Рифтовая долина в Кении (часть внутриконтинентального хребта, пересекающего страну с севера на юг). Исследователи называют факторами успеха бегунов в этих регионах высокоинтенсивные тренировки на больших высотах, бег с юного возраста и традиционную диету, богатую крахмалом.